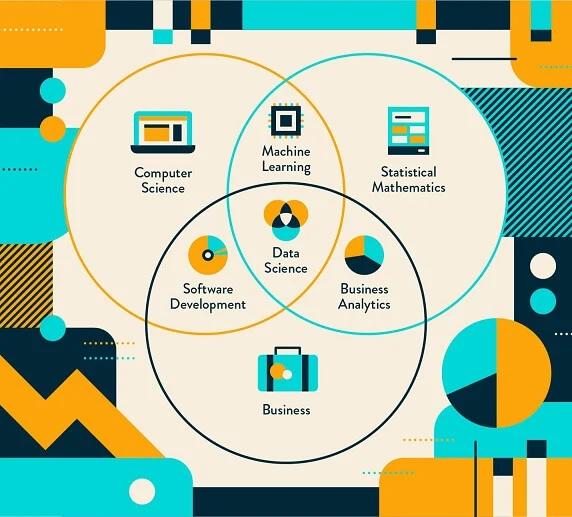
Data science is an essential part of any industry today, given the massive amounts of data that are produced. Data science is one of the most debated topics in the industries these days. Its popularity has grown over the years, and companies have started implementing data science techniques to grow their business and increase customer satisfaction. In this article, we’ll learn what data science is, and how it works.
What Is Data Science ?
A groundbreaking study in 2013 reported 90% of the entirety of the world’s data has been created within the previous two years. Let that sink in. In just two years, we've collected and processed 9x the amount of information than the previous 92,000 years of human-kind combined. And it isn’t slowing down. It’s projected we’ve already created 2.7 zettabytes of data, and by 2022, that number will balloon to an astounding 84 zettabytes.
What do we do with all this data? How do we make it useful to us? What are its real-world applications? These questions are the domain of data science.
Every company will say they’re doing a form of data science, but what exactly does that mean? The field is growing so rapidly, and revolutionizing so many industries, it's difficult to fence in its capabilities with a formal definition, but generally, data science is devoted to the extraction of clean information from raw data for the formulation of actionable insights
Commonly referred to as the “oil of the 21st century," our digital data carries the most important in the field. It has incalculable benefits in business, research, and our everyday lives. Your route to work, your most recent Google search for the nearest coffee shop, your Instagram post about what you ate, and even the health data from your fitness tracker are all important to different data scientists in different ways. Sifting through massive lakes of data, looking for connections and patterns, data science is responsible for bringing us new products, delivering breakthrough insights, and making our lives more convenient.
Data Science Definition
Broadly, Data Science can be defined as the study of data, where it comes from, what it represents, and the ways by which it can be transformed into valuable inputs and resources to create business and IT strategies.
The Data Science Life Cycle
The image represents the five stages of the data science life cycle:
Capture: data acquisition, data entry, signal reception, data extraction.
Maintain: data warehousing, data cleansing, data staging, data processing, data architecture.
Process: data mining, clustering/classification, data modeling, data summarization
Analyze: exploratory/confirmatory, predictive analysis, regression, text mining, qualitative analysis
Communicate: data reporting, data visualization, business intelligence, decision making.
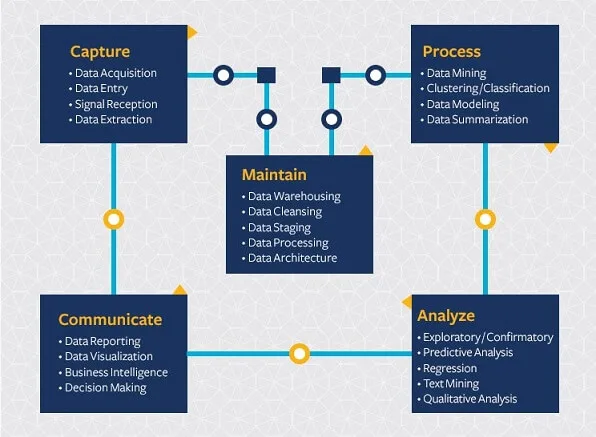
All five stages require different techniques, programs, and, in some cases, skillsets.
How Does Data Science Work?
Data science involves a plethora of disciplines and expertise areas to produce a holistic, thorough, and refined look into raw data. Data scientists must be skilled in everything from data engineering, math, statistics, advanced computing, and visualizations to be able to effectively sift through muddled masses of information and communicate only the most vital bits that will help drive innovation and efficiency.
Data scientists also rely heavily on artificial intelligence, especially its subfields of machine learning and deep learning, to create models and make predictions using algorithms and other techniques.
Prerequisites for Data Science
1. Machine Learning:
Machine learning is the backbone of data science. Data Scientists need to have a solid grasp of ML in addition to basic knowledge of statistics.
Should be aware of some machine learning algorithms which are beneficial in understanding data science clearly. The most basic and essential ML algorithms a data scientist use include:
- Regression: is an ML algorithm based on supervised learning techniques. The output of regression is a real or continuous value. For example, predicting the temperature of a room.
- Clustering: is an ML algorithm based on unsupervised learning techniques. It works on a set of unlabeled data points and groups each data point into a cluster.
- Decision Tree: refers to a supervised learning method used primarily for classification. The algorithm classifies the various inputs according to a specific parameter. The most significant advantage of a decision tree is that it is easy to understand, and it clearly shows the reason for its classification.
- Support Vector Machines (SVMs): are also a supervised learning method used primarily for classification. SVMs can perform both linear and non-linear classifications.
- Naive Bayes: is a statistical probability-based classification method best used for binary and multi-class classification problems.

2. Modeling:
Mathematical models enable you to make quick calculations and predictions based on what you already know about the data. Modeling is also a part of ML and involves identifying which algorithm is the most suitable to solve a given problem and how to train these models.

3. Statistics:
Statistics are at the core of data science. A sturdy handle on statistics can help you extract more intelligence and obtain more meaningful results.
4. Programming:
Some level of programming is required to execute a successful data science project. The most common programming languages are Python, and R. Python is especially popular because it’s easy to learn, and it supports multiple libraries for data science and ML.

5. Databases:
As a capable data analyst, you need to understand how databases work, how to manage them, and how to extract data from them.

Essential Data Science Skills for Success in Today's Industries
| Field | Skills | Tools |
|---|---|---|
| Data Analysis | R, Python, Statistics | SAS, Jupyter, R Studio, MATLAB, Excel, RapidMiner |
| Data Warehousing | ETL, SQL, Hadoop, Apache Spark | Informatica/ Talend, AWS Redshift |
| Data Visualization | R, Python libraries | Jupyter, Tableau, Cognos, RAW |
| Machine Learning | Python, Algebra, ML Algorithms, Statistics | Spark MLib, Mahout, Azure ML studio |
Need of Data Science for Businesses
We have come a long way from working with small sets of structured data to large mines of unstructured and semi-structured data coming in from various sources. The traditional Business Intelligence tools fall short when it comes to processing this massive pool of unstructured data. Hence, Data Science comes with more advanced tools to work on large volumes of data coming from different types of sources such as financial logs, multimedia files, marketing forms, sensors and instruments, and text files.
Mentioned below are relevant use-cases which are also the reasons behind Data Science becoming popular among organizations:
- Data Science has myriad applications in predictive analytics. In the specific case of weather forecasting, data is collected from satellites, radars, ships, and aircraft to build models that can forecast weather and predict impending natural calamities with great precision. This helps in taking appropriate measures at the right time and avoid maximum possible damage.
- Product recommendations have never been this precise with the traditional models drawing insights out of browsing history, purchase history, and basic demographic factors. With data science, vast volumes and a variety of data can train models better and more effectively to show more precise recommendations. better and more effectively to show more precise recommendations.
- Data Science also aids in effective decision-making. Self-driving or intelligent cars are a classic example. An intelligent vehicle collects data in real-time from its surroundings through different sensors like radars, cameras, and lasers to create a visual (map) of its surroundings. Based on this data and advanced Machine Learning algorithm, it takes crucial driving decisions like turning, stopping, speeding, etc.

Data Science Applications

Read more blogs here