Companies like Amazon, Microsoft, and Google have proven to us that we can trust them with our personal data. Now it’s time to reward that trust by giving them complete control over our computers, toasters, and cars.
Allow me to introduce you to “edge” computing.
Edge is a buzzword. Like “IoT” and “cloud” before it, edge means everything and nothing. But we’ve been watching some industry experts on YouTube, listening to some podcasts, and even, on occasion, reading articles on the topic. And we think I’ve come up with a useful definition and some possible applications for this buzzword technology.
What is edge computing?
Edge computing is a networking philosophy focused on bringing computing as close to the source of data as possible to reduce latency and bandwidth use. In simpler terms, edge computing means running fewer processes in the cloud and moving those processes to local places, such as on a user’s computer, an IoT device, or an edge server. Bringing computation to the network’s edge minimizes the amount of long-distance communication that can happen between a client and server.
Why is Edge Computing Important?
Edge computing is important because it creates new and improved ways for industrial and enterprise-level businesses to maximize operational efficiency, improve performance and safety, automate all core business processes, and ensure “always-on” availability. It is a leading method to achieve the digital transformation of how you do business.
- Powers the next industrial revolution, transforming manufacturing and services
- Optimizes data capture and analysis at the edge to create actionable business intelligence.
- Creates a flexible, scalable, secure, and more automated technology, systems, and core business process environment.
- Promotes an agile business ecosystem that is more efficient, performs faster, saves costs, and is easier to manage and maintain.
Increasing computing power at the edge is the foundation needed to establish autonomous systems, enabling companies to increase efficiency and productivity while enabling personnel to focus on higher-value activities within the operation.
How does edge computing work?
Edge computing is all a matter of location. In traditional enterprise computing, data is produced at a client endpoint, such as a user's computer. That data is moved across a WAN such as the internet, through the corporate LAN, where the data is stored and worked upon by an enterprise application. Results of that work are then conveyed back to the client endpoint. This remains a proven and time-tested approach to client-server computing for most typical business applications.
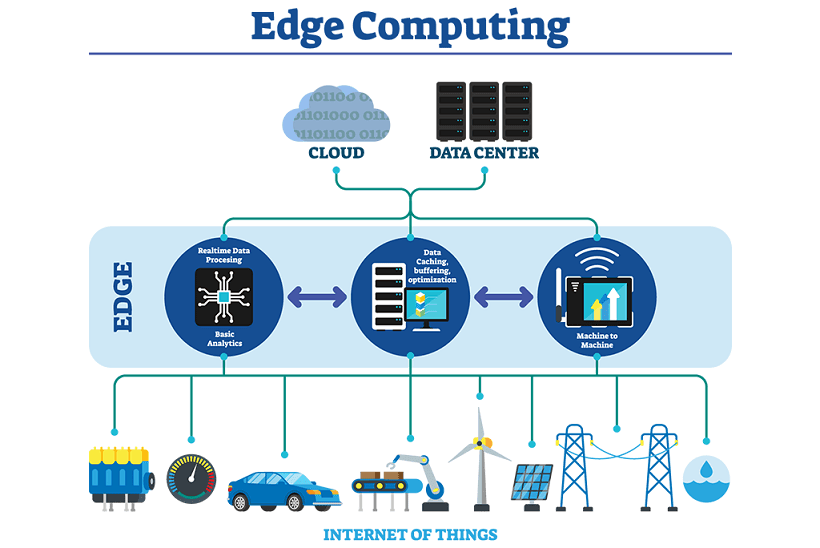
But the number of devices connected to the internet, and the volume of data being produced by those devices and used by businesses, is growing far too quickly for traditional data center infrastructures to accommodate. Gartner predicted that by 2025, 75% of enterprise-generated data will be created outside of centralized data centers. The prospect of moving so much data in situations that can often be time- or disruption-sensitive puts incredible strain on the global internet, which itself is often subject to congestion and disruption.
So, IT architects have shifted focus from the central data center to the logical edge of the infrastructure -- taking storage and computing resources from the data center and moving those resources to the point where the data is generated. The principle is straightforward: If you can't get the data closer to the data center, get the data center closer to the data. The concept of edge computing isn't new, and it is rooted in decades-old ideas of remote computing -- such as remote offices and branch offices -- where it was more reliable and efficient to place computing resources at the desired location rather than rely on a single central location.
Edge computing puts storage and servers where the data is, often requiring little more than a partial rack of gear to operate on the remote LAN to collect and process the data locally. In many cases, the computing gear is deployed in shielded or hardened enclosures to protect the gear from extremes of temperature, moisture, and other environmental conditions. Processing often involves normalizing and analyzing the data stream to look for business intelligence, and only the results of the analysis are sent back to the principal data center.
Edge computing use cases
Much of the technology we use today for entertainment and business, from content delivery systems and smart technology to gaming, 5G, or predictive maintenance, incorporate some form of edge computing technology.
Streaming music and video platforms, for example, often cache information to lower latency, offering more network flexibility when it comes to user traffic demands.
Manufacturers benefit from edge computing by keeping a closer eye on their operations. Edge computing enables companies to closely monitor equipment and production lines for efficiency and, in some cases, detect failures before they happen,helping avoid costly delays due to downtime. Similarly, you can also see edge computing being used in healthcare to look after patients, giving physicians more real-time insight into people’s health without the need to send their information to a third-party database for processing. Elsewhere, oil and gas companies can keep watch of their assets and avoid costly complications.
Smart home construction uses edge computing solutions as well. More and more devices need to communicate and process data in a localized network, especially devices like voice assistants. Without the help of decentralized processing power, Amazon Alexa and Google Assistant would take far more time to find requested answers for users.
Benefits of Edge Computing
1. Speed and Latency
The longer it takes to process data, the less relevant it is. In the case of the autonomous vehicle, time is of the essence and most of the data it collects and requires is useless after a couple of seconds. Milliseconds matter, especially on a busy roadway. Milliseconds also matter in the digital factory where intelligence-based systems perpetually monitor all aspects of the manufacturing process to ensure data consistency. In many cases, there isn’t time to round trip data back and forth between the cloud. Situations such as equipment failures and hazardous incidents call for the instantaneous analysis of data. Confining data analysis to the edge where it is created eliminates latency, which translates into faster response times. This makes your data more relevant, useful, and actionable. Edge computing also reduces the overall traffic loads of your enterprise at large, which improves performance for all your enterprise applications and services.
2. Security
When all your data must eventually feed to its cloud analyzer through a single pipe, the critical business and operating processes that rely on actionable data are highly vulnerable. As a result, a single DDoS attack can disrupt entire operations for a multinational company. When you distribute your data, analysis tools across the enterprises, you distribute the risk as well. While it can be argued that edge computing expands the potential attack surface for would-be hackers, it also diminishes the impact on the organization. Another inherent truth is that when you transfer less data, there is less data that can be intercepted. The proliferation of mobile computing has made enterprises much more vulnerable because company devices are now transported outside of the protected firewall perimeter of the enterprise. When data is analyzed locally, it remains protected by the security blanket of the on-premise enterprise. Edge computing also helps companies overcome the issues of local compliance and privacy regulations as well as the issue of data sovereignty.
3. Cost Savings
Since all data is not the same and does not contain the same value, how does one justify spending the same amount of money on all of it when it comes to transporting, managing, and securing it? While some data is critical to your operations, some are nearly expendable. Edge computing allows you to categorize your data from a management perspective. By retaining as much data within your edge locations, you reduce the need for costly bandwidth to connect all your locations, and bandwidth translates directly into dollars. Edge computing isn’t about eliminating the need for the cloud, it is about optimizing the flow of your data to maximize your operating costs. Edge computing also helps to reduce some level of data redundancy. Data that is created at the edge must be stored there at least temporarily. When sent to the cloud, it must be stored again, creating levels of redundancy. When you reduce redundant storage, you reduce redundant cost.
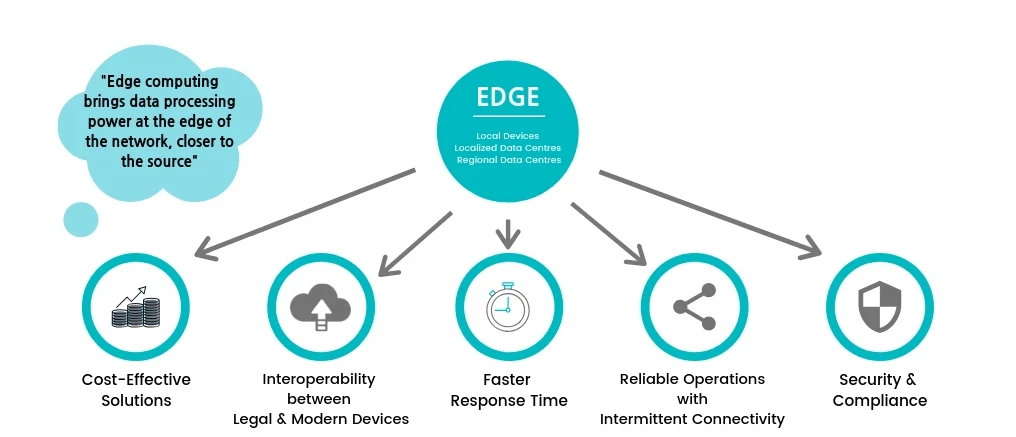
4. Greater Reliability
The world of IoT includes some remote territories comprised of rural and less than optimal environments concerning internet connectivity. When edge devices can locally store and process ensuing data, it improves reliability. Prefabricated micro data centers are built today to operate in just about any environment. This means that temporary disruptions in intermittent connectivity will not impact smart device operations just because they lost connection to the cloud. In addition, every site has some built-in limitation to the amount of data that can be transmitted at one time. Although your bandwidth demands may not be tested yet, the exponential growth in generated data will push bandwidth infrastructure to the limit in the future for many enterprises.
5. Scalability
Although the idea that edge computing offers an advantage of scalability may seem contrary to promoted theory, it makes sense. Even for cloud computing architectures, data must first be forwarded to a centrally located data center in most cases. Expanding or even just modifying dedicated data centers is an expensive proposition. What’s more, IoT devices can be deployed along with their processing and data management tools at the edge in single implantation, rather than waiting on the coordination of efforts from personnel located at multiple sites.
Privacy and security
From a security standpoint, data at the edge can be troublesome, especially when it’s being handled by different devices that might not be as secure as centralized or cloud-based systems. As the number of IoT devices grows, it’s imperative that IT understands the potential security issues and makes sure those systems can be secured. This includes encrypting data and employing access-control methods and possibly VPN tunneling, which can be cost-effective with the cheapest monthly VPNs available.
Furthermore, differing device requirements for processing power, electricity, and network connectivity can have an impact on the reliability of an edge device. This makes redundancy and failover management crucial for devices that process data at the edge to ensure that the data is delivered and processed correctly when a single node goes down.
The Future of Edge Computing
Shifting data processing to the edge of the network can help companies take advantage of the growing number of IoT edge devices, improve network speeds, and enhance customer experiences. The scalable nature of edge computing also makes it an ideal solution for fast-growing, agile companies, especially if they’re already making use of colocation data centers and cloud infrastructure.
By harnessing the power of edge computing, companies can optimize their networks to provide flexible and reliable service that bolsters their brand and keeps customers happy.
Edge computing offers several advantages over traditional forms of network architecture and will surely continue to play an important role for companies going forward. With more and more internet-connected devices hitting the market, innovative organizations have likely only scratched the surface of what’s possible with edge computing.
Read more blogs here