The ELK Stack, comprising Elasticsearch, Logstash, and Kibana, is a powerful open-source trio designed for centralized logging, data analysis, and visualization. Elasticsearch serves as a distributed search and analytics engine, capable of handling large volumes of data in real-time. Logstash facilitates data ingestion, transformation, and enrichment from diverse sources. Kibana complements them by providing an intuitive interface for data visualization, dashboard creation, and real-time monitoring. Together, these tools offer organizations a robust solution for exploring, analyzing, and deriving insights from their data, making the ELK Stack a popular choice for modern log management and data analytics workflows.
The ELK Stack traces its origins to the early 2010s when Shay Banon created Elasticsearch as a distributed search and analytics engine. Later, Logstash and Kibana were integrated to form the ELK Stack, providing a comprehensive solution for log management, data analysis, and visualization. Over time, the stack has evolved with regular updates and community contributions, becoming a staple in the realm of open-source data analytics tools.
Understanding Elasticsearch
Elasticsearch, at its core, is a distributed, RESTful search and analytics engine built on Apache Lucene. Its primary purpose is to efficiently index, search, and analyze large volumes of data in real-time. Elasticsearch boasts numerous features, including near real-time search capabilities, support for complex queries, scalability through sharding and replication, multi-tenancy support, and a rich set of APIs for data manipulation and management. Its architecture comprises nodes forming a cluster, each node capable of performing indexing, searching, and coordinating tasks, shards that spread across indices speeding up the search process. This distributed nature enables horizontal scalability and fault tolerance, making Elasticsearch a cornerstone in modern data analytics infrastructures.

Visualizing Data with Kibana
Kibana, an integral component of the ELK Stack, empowers users to visualize and explore their data through intuitive dashboards and visualizations. Its user-friendly interface allows for effortless creation of various chart types, including line, bar, pie, and geographical maps, facilitating deep insights into data trends and patterns. Kibana's dashboard feature enables users to compile multiple visualizations into a single, cohesive view, providing comprehensive monitoring and analysis capabilities. Additionally, Kibana supports real-time data visualization, allowing users to monitor streaming data as it arrives. With its rich customization options, including theming, layouts, and interaction controls, Kibana offers unparalleled flexibility in tailoring visualizations to specific use cases, making it an indispensable tool for data-driven decision-making.

Setting Up the ELK Stack: A Comprehensive Guide for Beginners
To set up Elasticsearch on Windows, begin by downloading the appropriate version from the official Elasticsearch website. Choose the Windows version and download the ZIP archive. Once downloaded, extract the contents of the ZIP file to a directory of your choice, such as C:\elasticsearch.
To start Elasticsearch, open a Command Prompt with administrative privileges. Navigate to the bin directory within your Elasticsearch folder by using the command cd C:\elasticsearch\bin. Execute the elasticsearch.bat file to start the Elasticsearch service. Keep an eye on the console output for any errors. If everything is set up correctly, you should see logs indicating that Elasticsearch is running.
Finally, verify your installation by opening a web browser and navigating to http://localhost:9200. If Elasticsearch is running properly, you will see a JSON response with details about your cluster, confirming that the setup is successful. By following these detailed steps, you should have Elasticsearch up and running on your Windows machine without any issues.

Use Cases
One primary use case for the ELK Stack is log and event data analysis. Organizations utilize it to collect logs from various sources, centralize them, and perform real-time analysis, which helps in identifying and troubleshooting system issues quickly. It’s also used for application monitoring, enabling developers to track performance metrics and detect anomalies or bottlenecks in real-time.
Security information and event management (SIEM) is another significant use case. Companies leverage ELK to monitor security events and alerts, helping to detect and respond to potential security threats. Its capability to handle large volumes of data makes it ideal for cybersecurity applications.
Big companies like Netflix, LinkedIn, and Cisco use the ELK Stack extensively. Netflix employs it for operational insights and troubleshooting, processing trillions of events daily. LinkedIn uses ELK for monitoring system performance and security. Cisco leverages it to manage logs and gain insights into network operations. These examples illustrate the scalability and versatility of the ELK Stack in handling extensive data needs across various industries.
Features of Elasticsearch
In the field of data management, Elasticsearch serves as a dynamic powerhouse, empowering users to handle vast volumes of data efficiently. Let's delve into how users can leverage Elasticsearch to master their data challenges and needs.
Firstly, data ingestion sets the stage. Elasticsearch employed BKD tree-based document-like database to handle data storage. So, if you’ve worked with MongoDB, it’ll be easy to relate to this data structure. Elasticsearch offers multiple avenues for data ingestion, whether it's through Logstash for log data, Beats for lightweight data shippers, or direct indexing via APIs. Once ingested, Elasticsearch's indexing engine swiftly organizes data into searchable documents, leveraging inverted indices for rapid retrieval.
Next, querying becomes paramount. Elasticsearch's Query DSL equips users with a versatile toolkit for crafting intricate searches. From simple full-text queries to complex aggregations and geospatial searches, Elasticsearch caters to diverse use cases with ease. Users can fine-tune their queries to extract precise insights from their data reservoirs. These insights are polled on the basis of precision and recall, the combination of which determines the relevance of the search result. Every result, represented in the form of a document also consists of a “score” that enumerates its relevance.
figure 1. A simple search query
GET /_search
{
"query": {
"match": {
"message": {
"query": "this is a test"
}
}
}
}
Moreover, data management extends beyond searching. Elasticsearch facilitates efficient data exploration through aggregations, enabling users to derive meaningful metrics and trends from their datasets. With the ability to visualize these insights in Kibana, Elasticsearch completes the loop, transforming raw data into actionable intelligence.
Figure 2. An aggregation query
GET /_search
{
"aggs": {
"genres": {
"terms": { "field": "genre" }
}
}
}
Architecturally, Elasticsearch's distributed nature ensures scalability and resilience. Clusters of interconnected nodes distribute data across shards, enabling horizontal scalability and fault tolerance.
In essence, Elasticsearch empowers users to navigate the data landscape with confidence, offering a robust toolkit for ingestion, querying, exploration, and visualization. With Elasticsearch at their disposal, users can harness the full potential of their data assets, driving informed decisions and unlocking new opportunities for innovation.
Elasticsearch’s advanced features
Elasticsearch's advanced features elevate it beyond a mere search engine, transforming it into a comprehensive data analytics powerhouse. Among its arsenal of capabilities, Elasticsearch offers advanced search functionalities like full-text search, fuzzy matching, and relevance scoring, enabling users to unearth precise insights from their data troves.
Figure 3. A compound query using bool.
Post _search
{
"query": {
"bool": {
"must": [
{
"match": {
"field1": "value1"
}
},
{
"match": {
"field2": "value2"
}
}
],
"should": [
{
"match": {
"field3": "value3"
}
}
],
"must_not": [
{
"match": {
"field4": "value4"
}
}
]
}
}
}
Moreover, its aggregations framework empowers users to perform complex analytics, from basic metrics to sophisticated statistical analyses. Elasticsearch's support for geospatial queries further enriches its querying capabilities, facilitating location-based analysis and visualization. Additionally, its near real-time indexing ensures that data is always up-to-date, enabling organizations to make decisions based on the latest information. With security features like role-based access control and encryption, Elasticsearch ensures data integrity and confidentiality. Combined with its scalability, fault tolerance, and ecosystem of plugins, Elasticsearch emerges as an indispensable tool for organizations seeking to extract maximum value from their data assets, enabling them to stay ahead in today's data-driven landscape.
Relevance of a Search
Elasticsearch balances precision and recall to generate relevant search results. Precision measures the accuracy of the retrieved documents, while recall assesses the completeness. Elasticsearch uses its scoring algorithm, based on Term Frequency-Inverse Document Frequency (TF-IDF) and other relevance models, to rank documents by relevance.
To optimize precision, it focuses on retrieving the most relevant documents by considering factors like term frequency and field length. For recall, Elasticsearch ensures a broad retrieval of documents that match the search criteria, using techniques like tokenization and stemming. Customizable scoring functions and query types allow fine-tuning to balance precision and recall according to specific needs. Elasticsearch offers two primary methods for searching and analyzing data: queries and aggregations.
Queries
Queries in Elasticsearch are designed to retrieve documents that match specific criteria. They are the backbone of search functionality, enabling users to perform precise and efficient searches. There are various types of queries, including:
- Match Query: used for full-text search, matching documents that contain a specified term.
- Term Query: searches for exact matches in structured data, ideal for filtering.
- Range Query: finds documents with fields within a specified range, useful for date and numeric ranges.
- Bool Query: combines multiple queries with logical operators (must, should, must_not), allowing for complex search conditions.
Elasticsearch's robust query capabilities allow users to construct detailed searches, balancing precision and recall to find the most relevant documents.
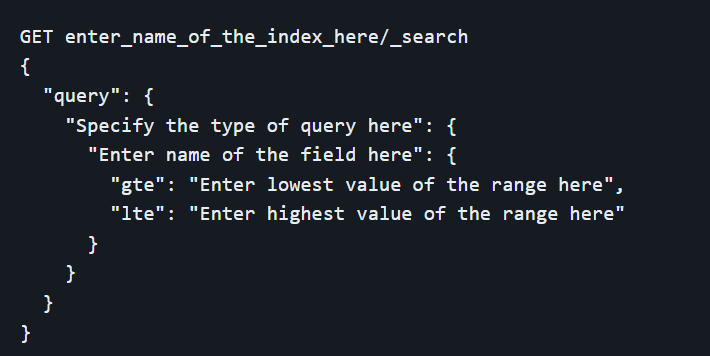
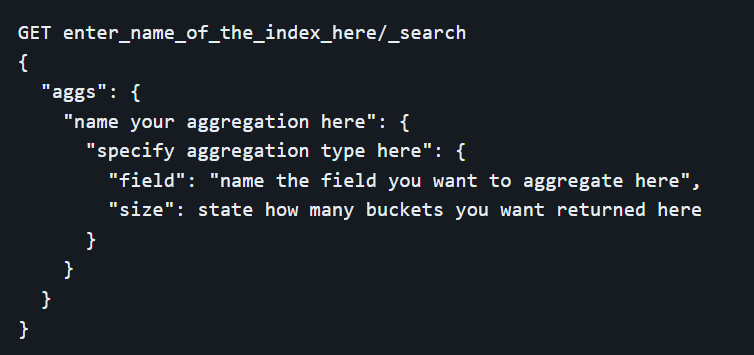
Aggregations (Aggs)
Aggregations, or "aggs," provide a way to perform complex data analysis and summaries on large datasets. Unlike queries, which retrieve specific documents, aggregations focus on calculating metrics and statistics over the entire dataset or subsets of it. Key types of aggregations include:
- Metrics Aggregations: Compute statistical data, such as average, sum, min, max, and count, on numeric fields.
- Bucket Aggregations: Group documents into buckets based on field values. Examples include terms aggregation (categorical data), date histogram (time-based data), and range aggregation (numeric ranges).
- Pipeline Aggregations: Allow for the processing of the output of other aggregations, enabling advanced calculations like moving averages or cumulative sums.
Using aggregations, users can perform in-depth analyses such as trend analysis, anomaly detection, and data summarization, providing powerful insights into their data.
Together, queries and aggregations in Elasticsearch offer a comprehensive toolkit for both searching and analyzing data, making it an invaluable resource for applications requiring sophisticated data handling capabilities.
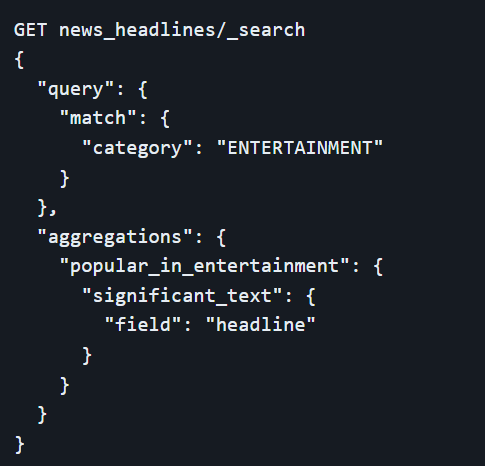
Full Text Queries
Elasticsearch provides a robust suite of full-text search capabilities through various query types, notably `match`, `match_query`, `multi_match`, and `bool`. Each type serves a specific purpose and can be combined to perform complex and nuanced searches.
The `match` query is the cornerstone of full-text search in Elasticsearch. It is designed to analyze the input text, breaking it down into individual terms and searching for documents that contain these terms. This analysis typically involves tokenization and other processes like stemming and removing stop words. For instance, if you search for "search text" using a match query, Elasticsearch will find documents where these words appear, ranking them by relevance based on factors like term frequency and field length.
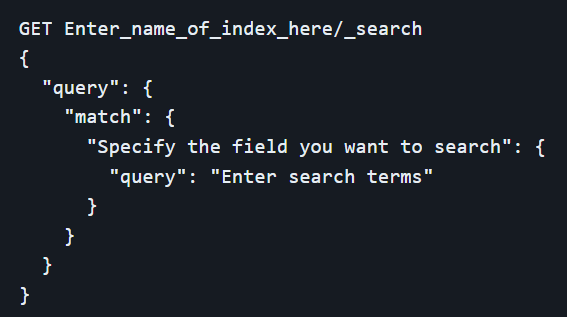
Expanding on the basic `match` query, `match_query` allows for greater refinement. It includes options to control how terms are matched, such as specifying that all terms must be present (using the `and` operator) or setting the minimum number of terms that need to be matched. This level of control is particularly useful for fine-tuning search results, ensuring that only the most relevant documents are retrieved.
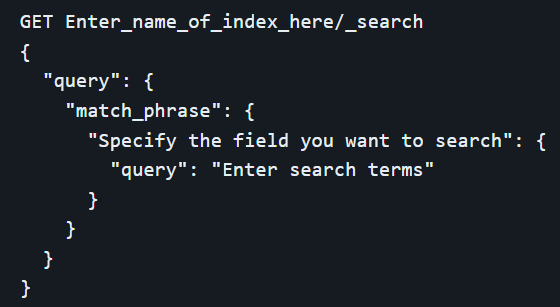
The `multi_match` query extends the functionality of the match query to multiple fields within a document. This is particularly useful when the information sought could be spread across various fields, such as titles, descriptions, and content. By searching across multiple fields simultaneously and combining the relevance scores from each field, the multi_match query provides a comprehensive approach to full-text search. This is crucial in scenarios where the relevant information might not be confined to a single field, thereby enhancing the search scope and accuracy.
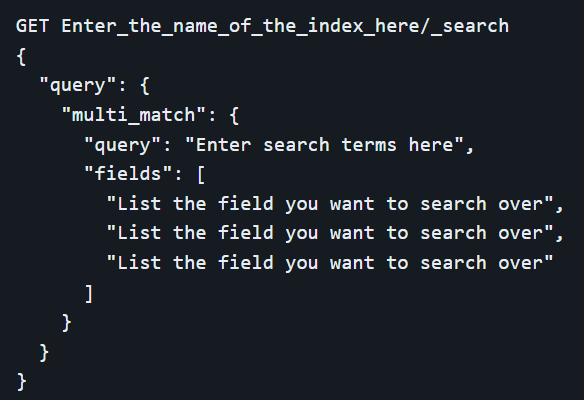
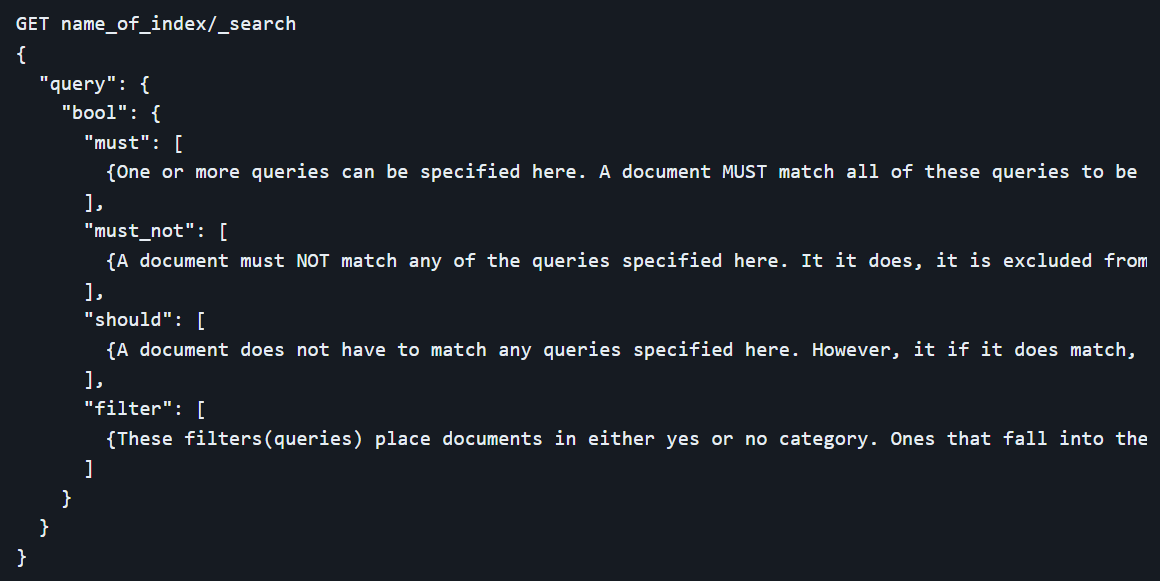
The `bool` query is a powerful tool that combines multiple queries using Boolean logic. It supports four main clauses: `must`, `should`, `must_not`, and `filter`. Each clause serves a different purpose in the query structure. The `must` clause requires that the document matches the specified queries, while the `should` clause boosts the relevance of documents that match. The `must_not` clause excludes documents that match the specified queries, and the `filter` clause, similar to `must`, is used for non-scoring criteria, enhancing efficiency. This flexibility allows for the creation of highly complex and targeted search conditions, catering to sophisticated search requirements.
In summary, Elasticsearch’s `match`, `match_query`, `multi_match`, and `bool` queries provide a comprehensive toolkit for full-text search. The `match` query handles basic full-text searches, while `match_query` offers refined control. The `multi_match` query allows for searching across multiple fields, and the `bool` query combines multiple search criteria using Boolean logic. Together, these queries enable Elasticsearch to perform powerful and flexible full-text searches, making it an invaluable tool for applications requiring nuanced data retrieval and analysis.
Aggregations
Elasticsearch's aggregation framework is an integral feature that empowers users to perform detailed and complex data analysis on their datasets. This capability is essential for deriving insights from large volumes of data, transforming raw information into actionable intelligence. The framework operates by computing various metrics and creating categorized groups of data, known as buckets, based on the documents that match a specified query.
Metric Aggregations
Metric aggregations in Elasticsearch serve the purpose of calculating statistical values from the data fields. Among these, the sum aggregation is fundamental as it computes the total sum of numeric values for a specified field. For example, an organization might use this to calculate the total revenue from sales transactions over a specific period.
The average aggregation, another critical metric, determines the mean value of a numeric field. This is particularly useful for analyzing average customer spend per order, average ratings for products, or average time spent on a website.
Minimum and maximum aggregations identify the lowest and highest values within a field, respectively. These metrics are valuable for understanding the range of data, such as identifying the least and most expensive products sold, or the earliest and latest dates in a dataset.
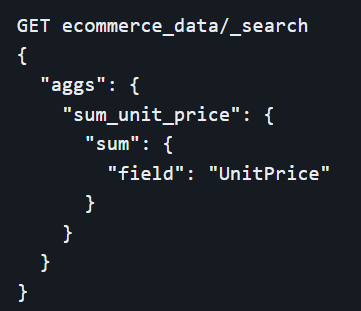
The stats aggregation provides a comprehensive statistical overview by offering the minimum, maximum, average, sum, and count of values in a single operation. This aggregation is particularly useful when a broad statistical summary of the data is needed quickly.
Cardinality aggregation, on the other hand, counts the number of unique values in a field. This metric is essential for understanding the diversity/uniqueness within a dataset, such as counting the number of unique visitors to a website or the number of distinct products sold.
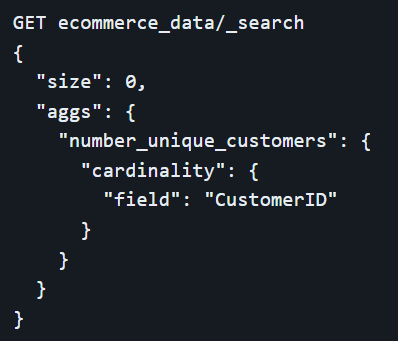
Bucket Aggregations
Bucket aggregations in Elasticsearch allow data to be grouped into various categories, providing a deeper level of analysis. The terms aggregation groups documents by unique values within a field. For instance, it can categorize sales data by product categories or user visits by country, offering insights into the distribution of these values.
Range aggregation groups documents into predefined ranges. This is useful for categorizing numeric data, such as sales amounts into different price brackets or dates into specified intervals, facilitating an understanding of how data is distributed across ranges.
Date histogram aggregation is particularly effective for time-series data analysis. It groups documents into time-based buckets, such as days, weeks, or months. This aggregation is crucial for tracking trends over time, such as analyzing website traffic patterns or sales trends across different periods.
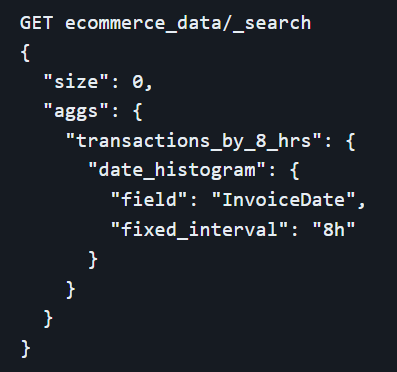
Filters aggregation allows the creation of buckets based on different filter criteria. Each bucket represents a specific filter condition, enabling multifaceted analysis by applying multiple filters simultaneously.
Query and Aggregations
Aggregations are generally applied to the results of a query. The query filters the dataset, selecting the subset of documents to be analyzed, and then the aggregations perform their calculations on this subset. For example, a query might select all active sales records from the past year, and aggregations could then calculate the total revenue, average order value, and categorize sales by product category.
Mapping
Elasticsearch mapping is a critical feature that defines how documents and their fields are stored and indexed within an Elasticsearch index. It acts as a blueprint, outlining the structure and data types of the fields, which is essential for effective indexing and search capabilities.
Mappings play a vital role in ensuring data is stored in an optimal format, allowing Elasticsearch to perform searches and aggregations efficiently. When data is indexed without a proper mapping, Elasticsearch may make incorrect assumptions about data types, leading to suboptimal performance and inaccurate search results. For instance, treating a date field as a string could prevent range queries on dates, thus highlighting the importance of accurate mappings.
Creating mappings can be done manually or automatically. In dynamic mapping, Elasticsearch attempts to infer the data types of fields based on the first document indexed. While convenient, this method may not always assign the desired types, especially in complex schemas. Hence, manual
mapping is often preferred for better control and precision. Manual mapping involves explicitly defining the structure and types for each field in a JSON format before indexing documents. This ensures fields are correctly interpreted, enhancing search accuracy and performance.
The components of a mapping include field types, analyzers, and multi-fields. Field types specify the nature of data, such as `text` for full-text search, `keyword` for exact matches, `date` for dates, `integer` for numbers, and so on. Each type has specific attributes that can be fine-tuned, such as precision for numeric fields or format for date fields.
Analyzers play a crucial role in processing textual data. They break down text into tokens and apply filters to enhance search capabilities. Custom analyzers can be created to handle specific linguistic requirements, improving search relevance and accuracy.
Multi-fields allow a single field to be indexed in different ways for different use cases. For example, a `text` field can have a `keyword`
sub-field for exact matches while also supporting full-text search.
Properly defined mappings ensure data is indexed correctly, facilitating efficient and
accurate searches. By controlling field types, analyzers, and multi-fields, mappings enhance
Elasticsearch's ability to handle diverse data types and complex queries, making it an indispensable tool
for any data-intensive application.
Conclusion:
So far, we went through the basics and features of ELK stack and how they help us with our data query and analysis needs. I think it is safe to say that ELK is one of the more capable solutions out there, maintained and developed by an earnest team. But as the saying goes, where there’s one, there’s many, there are many more contenders who compete to gain our attention.
In conclusion, while the ELK stack is versatile and scalable, the best tool depends on your specific needs, budget, and data complexity. Evaluating and testing various options will help you choose the right platform, ensuring valuable insights and informed decision-making.
Read more blogs here